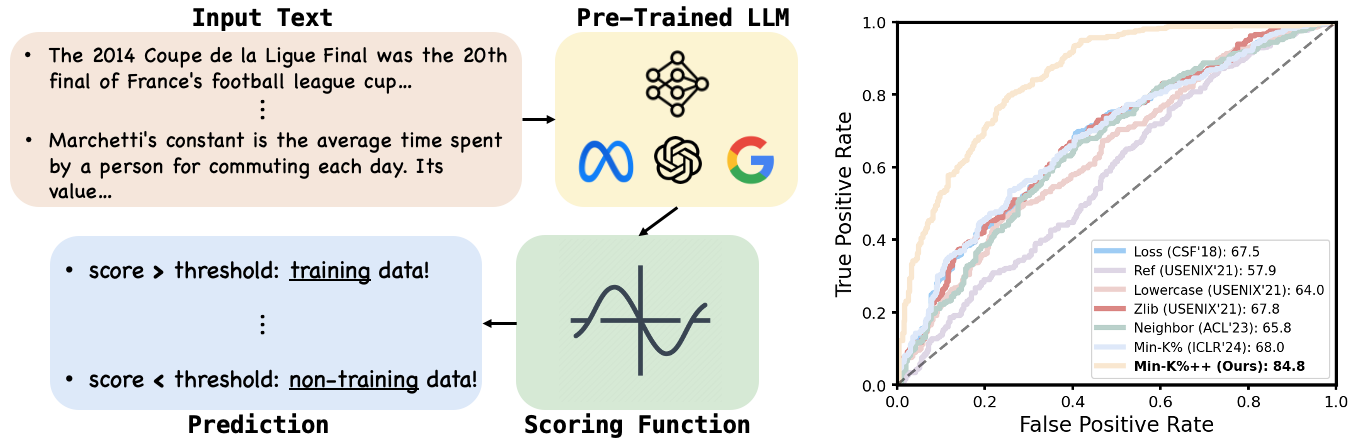
We propose a novel method for the detection of pre-training data of LLMs. This problem (see above figure left panel
for an illustration) has been receiving growing attention recently, due to its profound implications to copyrighted content detection,
privacy auditing, and evaluation data contamination.
Our method, named Min-K%++, is theoretically motivated by revisiting LLM's
training objective (maximum likelihood estimation, MLE) through the lens of score matching. We show that the general MLE training under continuous distribution
will tend to make training samples be (or locate near) the local maxima along each input dimension. Then, translating this insight into a practical method for LLMs,
we propose to detect training data by inspecting whether the tokens in the input text form modes (or have relatively high probability) under the conditional categorical distribution modeled by LLMs.
Empirically, Min-K%++ achieves state-of-the-art performance on the WikiMIA benchmark, outperforming existing approaches by large margin (showcased by the above figure right panel).
On the more challenging MIMIR benchmark, Min-K%++ is also the best among reference-free methods and performs on par with reference-based methods.
Our method, named Min-K%++, is theoretically motivated by revisiting LLM's training objective (maximum likelihood estimation, MLE) through the lens of score matching. We show that the general MLE training under continuous distribution will tend to make training samples be (or locate near) the local maxima along each input dimension. Then, translating this insight into a practical method for LLMs, we propose to detect training data by inspecting whether the tokens in the input text form modes (or have relatively high probability) under the conditional categorical distribution modeled by LLMs.
Empirically, Min-K%++ achieves state-of-the-art performance on the WikiMIA benchmark, outperforming existing approaches by large margin (showcased by the above figure right panel). On the more challenging MIMIR benchmark, Min-K%++ is also the best among reference-free methods and performs on par with reference-based methods.